⋱ Scale HK Lawmakers' Political Position
{Academic Graphs}: Rstudio, API
The Story
Having covered Hong Kong politics for three years, I’ve often wondered if there’s a way to read all the legislative transcripts at once.
Well, there is - sort of.
Quanteda, an R package for textual data analysis, can process thousands of pages of Hansard, breaking them down into tokens (the smallest units of text) and measuring the similarity of language used by different speakers. This allows us to map their ideological proximity.
It’s a powerful tool, and many academics have used it to analyse political texts. I figured Hong Kong’s Legislative Council transcripts would be a great dataset, given the region’s rapid political transformation, with pro-democracy lawmakers removed from the city’s legislature. Surely, these shifts would be reflected in Hansard.
And they are.
The Graph
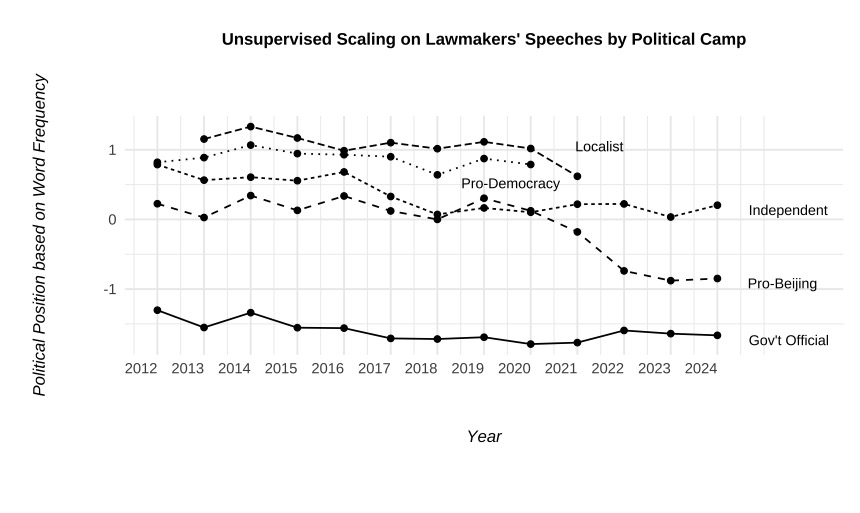
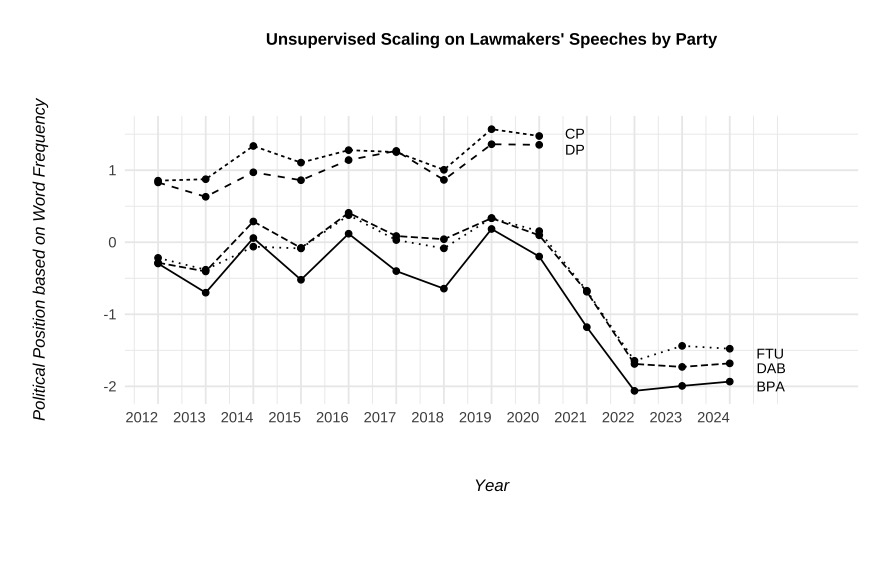
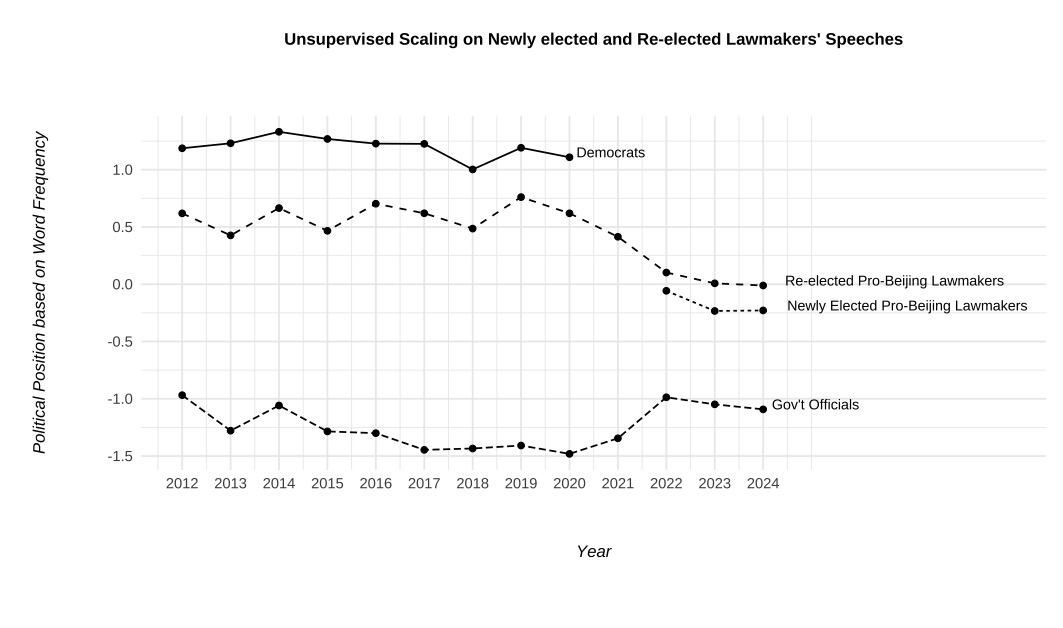
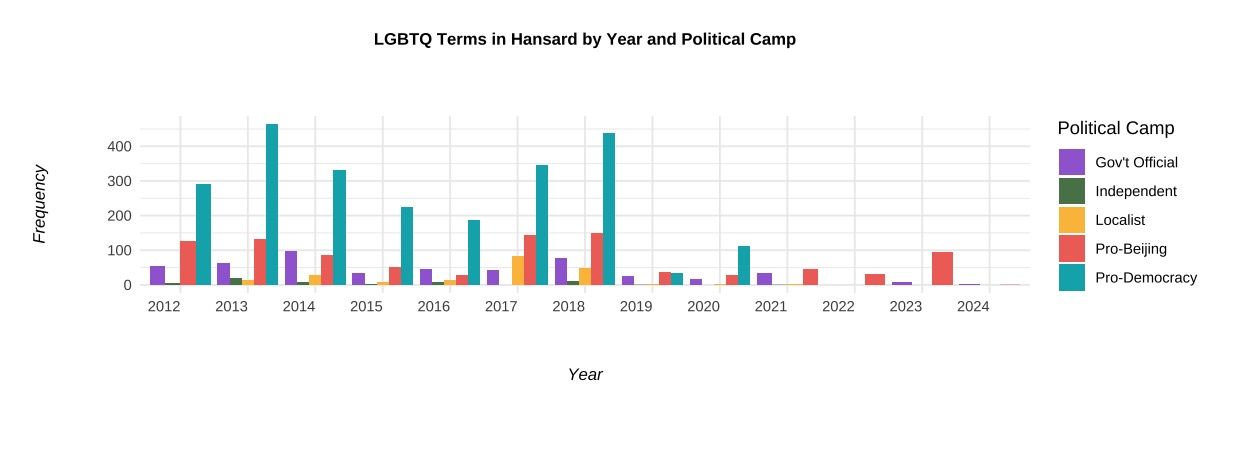
As shown in the graphs:
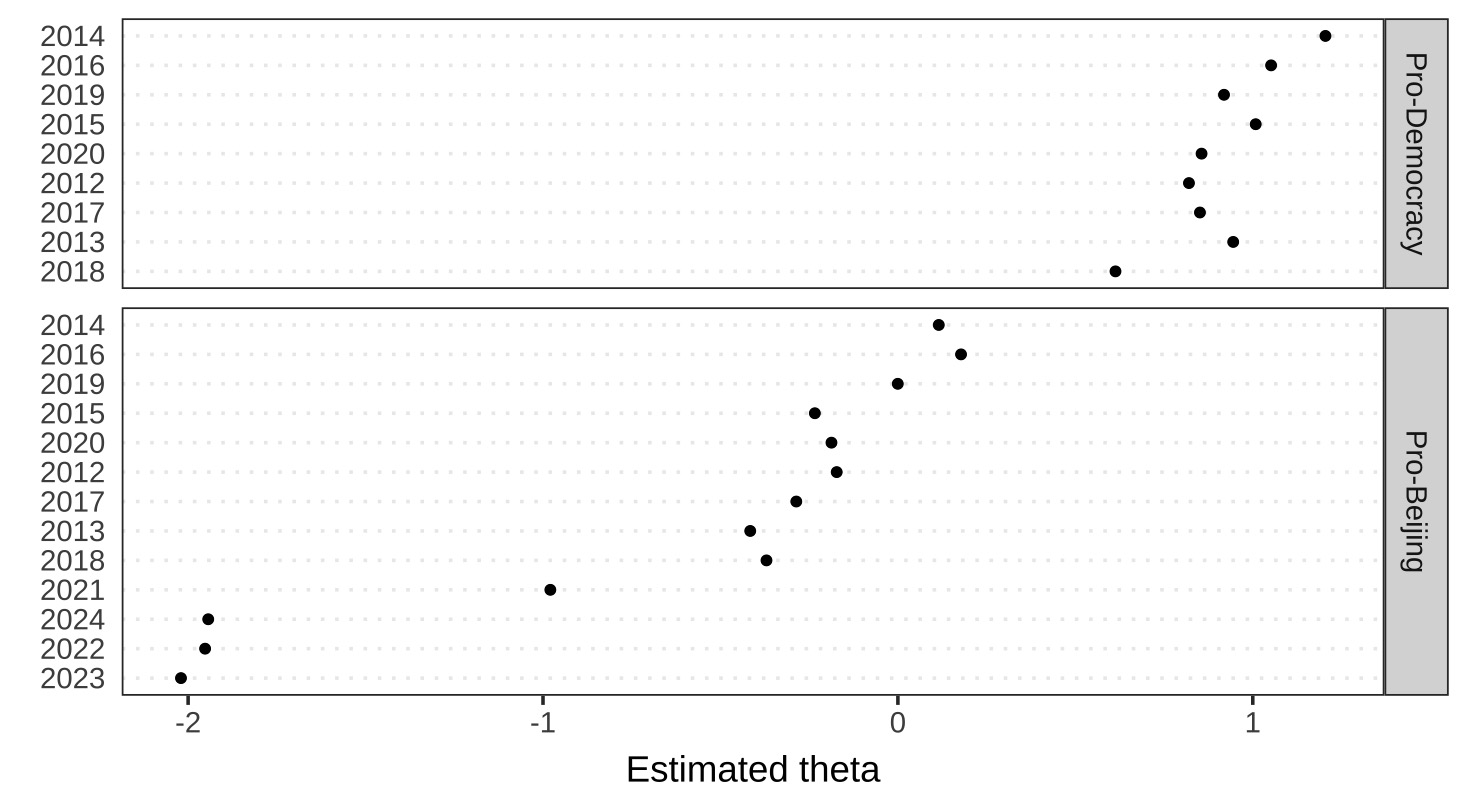
▍ Pro-Beijing lawmakers’ language has become much more similar to that of government officials (top left), particularly among newly elected legislators after the overhaul (top right).
▍ The difference between pro-democracy parties is relatively minor (top middle).
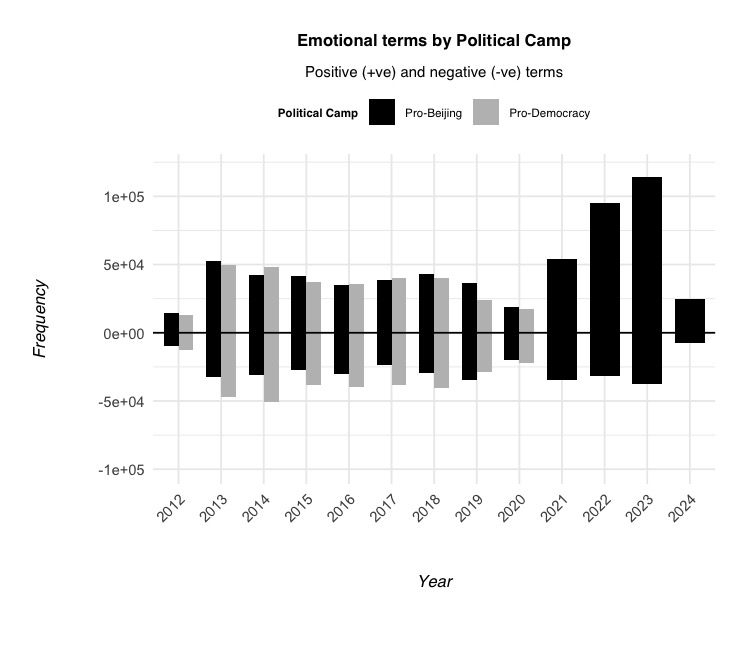
▍ Using a dictionary-based method, we see that the pro-Beijing camp used more positive language in the council compared to their own rhetoric before 2020 (bottom left).
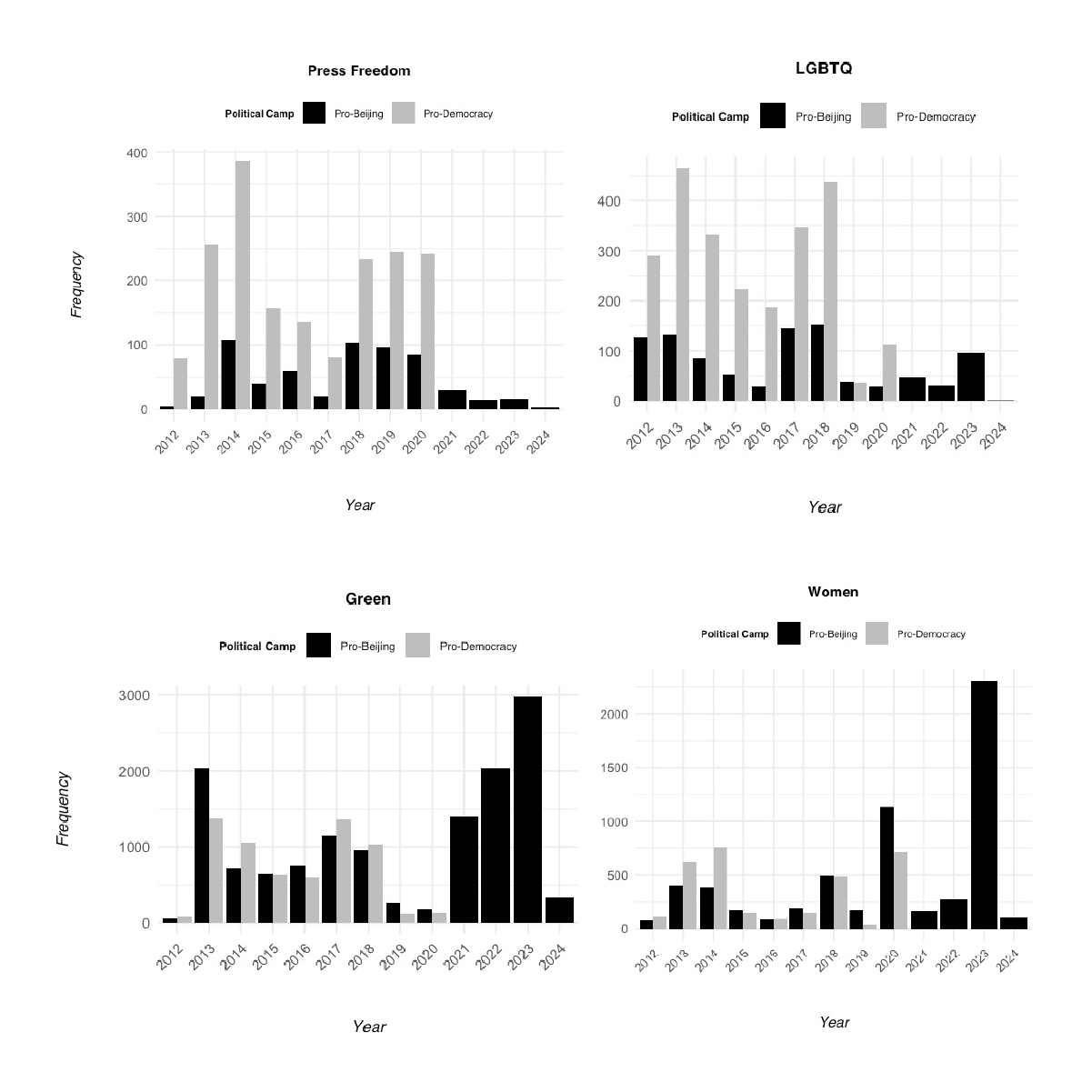
▍ Most pro-Beijing lawmakers also avoided discussing LGBTQ+ and press freedom - both sensitive topics for the Communist Party - but talked significantly more about green policies and women’s welfare (bottom middle).
While these results were somewhat expected, proving such shifts would be much harder without a quantitative text analysis tool like Quanteda.
| Data source: | Hong Kong Legislative Council | |
| Tools used: | Rstudio(Quanteda) | Python (Ckiptagger) |
Notes
⋱ I didn’t manually classify speeches as “pro-democracy” or “pro-Beijing.” The model simply mapped speakers based on linguistic similarity, using pro-democracy lawmakers and government officials as benchmarks to track shifts before and after the overhaul.
⋱ I analysed the Chinese version of Hansard for accuracy. Since Chinese, like Korean and Japanese, lacks natural spaces between words, I used a CKIP-style Chinese NLP tool for word segmentation.
⋱ This research formed the basis of my master’s dissertation in Political Science at LSE.